
Introduction
Most eligibility errors don't come from bad logic. They come from an employee whose job title changed in the HRIS three days ago, a dependent whose date of birth was entered with a typo, or a hire date that didn't sync before open enrollment closed. By the time someone catches it, the wrong coverage is already active.
Automated eligibility determination is the process by which software systems evaluate whether an individual qualifies for a benefit, coverage, or program, using predefined rules and real-time data, without a caseworker or administrator reviewing each case manually.
For HR Tech builders, benefits administration platforms, insurtechs, and TPAs, this isn't just an operational convenience. It's the difference between a scalable infrastructure and a compliance liability.
This guide covers how automated eligibility determination works end-to-end, what actually breaks it in practice, and when full automation isn't the right call. One pattern shows up consistently across all of it: when eligibility decisions go wrong, the rules engine is almost never the problem. The data pipeline feeding it is.
Key Takeaways
- Automated eligibility determination uses rules engines and real-time data to decide benefit qualification without per-case manual review.
- The most common failure point is stale or incomplete data, not the logic layer.
- Life events (new hires, terminations, dependent changes) are the primary re-determination triggers and must be captured in real time.
- Large employers run more than nine HR systems on average, creating a fragmentation problem that eligibility engines must solve.
- Batch sync platforms introduce accuracy and compliance risks that event-driven data pipelines eliminate.
What Is Automated Eligibility Determination?
At an operational level, the process works like this: a system ingests applicant or enrollee data, runs it through a decision logic layer (a rules engine or algorithm), and cross-references it against authoritative data sources. The system then returns an outcome, approved, denied, or pended, with no human reviewing the case first.
The goal is replacing slow, error-prone manual casework with consistent, scalable decisions that reduce coverage gaps, administrative overhead, and processing delays.
How It Differs from Auto-Enrollment and Verification
This term gets conflated with related but distinct processes:
- Auto-enrollment acts on an eligibility decision already made; it doesn't make the decision itself
- Eligibility verification API calls confirm a pre-existing status rather than evaluating whether someone qualifies
- Renewals automation re-determines eligibility for currently enrolled individuals on a scheduled basis, a subset of the broader process
The mechanics apply across benefit types, including:
- Medicaid and ACA marketplace plans
- Employer-sponsored health benefits
- FSA/HSA and COBRA
- Supplemental benefits
The underlying logic differs by program, but the pipeline structure follows the same pattern.
Why It Matters in Benefits and HR Tech
Benefits platforms and TPAs managing thousands of employer groups cannot process eligibility events manually at scale. New hires, qualifying life events, terminations, open enrollment. Each requires prompt action. Delays aren't just inconvenient; they create measurable risk.
What Breaks Without Automation
- Coverage gaps. New employees wait days or weeks for enrollment confirmation while technically uninsured
- Erroneous claims approvals. Terminated employees still showing as active in carrier systems, with claims paying out weeks after separation
- Compliance exposure. Eligibility data out of sync with payroll or HRIS records creates downstream failures in ACA reporting
The regulatory stakes are concrete. Two specific rules set the floor:
- ACA Section 6056: Per the IRS 2025 instructions, failure to e-file when required carries a penalty of $340 per return for Applicable Large Employers.
- COBRA election window: DOL guidance gives qualified beneficiaries 60 days to elect COBRA from the later of coverage loss or receipt of the election notice. A deadline automated termination logic must preserve exactly.
The Three-Way Data Problem
Employer-sponsored benefits involve a three-way data relationship: the employer's HRIS, the benefits platform, and the insurance carrier. All three must stay synchronized in near real time. This makes the integration layer, not just the rules engine, the critical infrastructure. A rules engine is only as accurate as the data feeding it: logically perfect logic applied to stale HRIS records still produces wrong eligibility outcomes.
How Automated Eligibility Determination Works
The end-to-end flow follows a consistent pattern regardless of benefit type:
Triggering event → Data ingestion → Rules evaluation → Outcome delivery → Downstream system sync

Here's what each step involves in practice.
Step 1: Event Trigger and Data Ingestion
Every determination begins with a triggering event: a new hire record created in the HRIS, a reported life event (marriage, dependent birth), a scheduled renewal date, or a termination. The system must capture this event and pull the associated employee, employer, and dependent data from source systems.
Platforms that rely on manual exports or nightly batch syncs introduce lag between the real-world event and the eligibility decision. During that window, coverage is incorrect: either extended to someone no longer eligible, or withheld from someone who is.
Event-driven systems handle this capture in real time via webhooks. Legacy platforms that only export files require a different approach: an SFTP-to-API bridge (such as Bindbee's) normalizes CSV, XML, and fixed-width formats into structured data served through the same API endpoints as direct integrations, keeping the ingestion layer consistent regardless of source system capability.
Step 2: Rules Engine Evaluation
The rules engine applies predefined eligibility logic against the ingested data. Common criteria include:
- Hours-worked thresholds and employment classification (full-time, part-time, variable-hour)
- Waiting periods by plan or employment type
- Dependent relationship types and age cutoffs
- Plan offering criteria by benefit class, location, or tenure
Accuracy here depends on two things: how precisely the business rules are codified, and whether the data inputs are clean, current, and structurally consistent across source systems.
Beyond normalized data delivery, platforms like Bindbee include built-in eligibility intelligence (ACA hours validation, waiting period calculation, benefit class assignment, and state-specific rules), reducing the compliance logic benefits platforms must build in-house.
Step 3: Outcome Delivery and System Sync
Once a determination is made, the result must reach every dependent system: carrier enrollment platforms, payroll (for deduction adjustments), the benefits portal, and any reporting layer.
Webhook-based notifications push eligibility changes to downstream systems in real time rather than waiting for the next scheduled sync. This matters because the gap between a real-world event and a system update is exactly where claims get paid for ineligible members or newly eligible employees get denied coverage.
Bindbee's webhook system fires an employee_data_changed event that captures termination dates, employment status changes, and the full range of life events:
- Marriage, divorce, and loss of other coverage
- Dependent birth, death, and age-out
All connected systems (COBRA admins, FSA/HSA providers, voluntary carriers, and payroll) receive these signals in real time, with structured event data eliminating manual eligibility-lookup work.
For carrier sync specifically, automating EDI 834 file generation at this step removes the manual creation-and-upload cycle that historically causes batch lag in carrier enrollment.
Key Factors and Common Challenges
Data Freshness
The most critical variable isn't rule complexity. It's data freshness. Eligibility logic may be correct, but if employment status, hours worked, or dependent data is stale, the determination will be wrong.
Monthly batch exports mean benefits decisions get made on information that's already weeks old. With incremental sync, a termination surfaces the same day, not 30 to 90 days later when a claims audit uncovers the overpayment. Clever Benefits documented exactly this pattern: CSV-based SFTP transfers meant benefits decisions were made on information that could be hours or days old.
Real-time or near-real-time sync doesn't eliminate all latency, but it collapses the risk window from weeks to hours.
Integration Fragmentation
Bersin research found that by 2021, large companies used more than nine HR systems of record on average, up from seven in 2017. Each system may use different field names, coding conventions, date formats, and update frequencies.
When an eligibility engine ingests data from three or four systems that each represent employment classification differently, inconsistencies compound fast.
A normalized data model solves this by mapping every source system's fields into a consistent schema: date format differences, pay frequency variations, and employment type codes handled automatically. That normalization is the operational prerequisite for reliable eligibility logic.
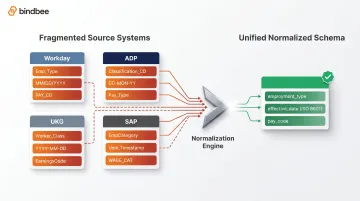
Budgie Health experienced this directly: connecting with HRIS platforms like UKG, Workday, and ADP in-house would have required several months of development time per system. By abstracting 30 HR and payroll integrations through Bindbee's unified API, their engineering team completed the integration layer in three days.
Rules Complexity Is Routinely Underestimated
Teams often build eligibility logic for the standard case and leave edge cases as manual workarounds:
- Part-time employees crossing hours thresholds mid-year
- Rehires with prior coverage histories
- Domestic partner benefits with state-specific qualification rules
- Mid-year plan changes with retroactive effective dates
Each manual workaround reintroduces human error into a system designed to eliminate it. Edge case handling needs to be scoped and codified upfront, or explicitly routed to a human review queue with defined escalation criteria.
Automated Terminations Require Oversight
Admins can correct a wrongful automated enrollment quickly. Wrongful terminations are a different matter. Incorrectly cutting coverage for an eligible employee carries legal and compliance exposure, particularly around COBRA.
The 60-day COBRA election window begins from the later of coverage loss or receipt of the election notice. Automated termination logic must sequence with COBRA notice generation and hold coverage status changes until qualifying-event workflows are satisfied. ThrivePass solved this by switching from batch 834 file processing to real-time Bindbee webhooks. Their claims now adjudicate against current eligibility data, and COBRA workflows trigger within the federally required notice window consistently.
When Automated Eligibility Determination May Fall Short
Full automation is the right default for high-volume, predictable eligibility events. It's the wrong default when applied indiscriminately.
Scenarios Where Automation Breaks Down
- Highly customized plan designs with employer-specific rules that can't be cleanly codified in a standard data model
- Complex eligibility histories like rehires, leaves of absence, and variable-hour workers, where automated logic frequently produces false outcomes
- Unreliable source data where the underlying HRIS records are known to contain errors or gaps
Custom field support addresses the first scenario. Bindbee pulls all custom fields from each HRIS and lets platforms map them to their own schema, so employer-specific eligibility parameters don't get lost in normalization. Even so, some plan designs require human judgment that can't be codified without substantial edge case work.
The Automation-Without-Investment Failure Pattern
The signal that automation is being applied by default rather than by design: teams implement it to reduce staffing costs but don't invest in data quality, rules validation, or exception-handling processes. The result is an initial drop in manual work followed by a rise in eligibility errors and member complaints that are more expensive to fix than the original manual process.
That failure pattern has a clear fix, but it requires intentional design, not just a different toolset.
The Hybrid Model
A hybrid approach captures the efficiency gains without sacrificing accuracy on edge cases:
- Automated straight-through processing handles new hires on standard plans, standard annual renewals, and predictable life events
- Human review queue handles flagged exceptions like complex histories, edge-case classifications, retroactive changes, and termination disputes
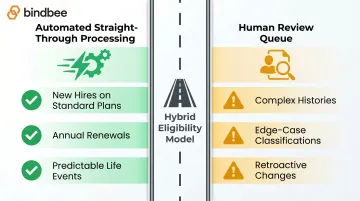
For most mid-market and enterprise benefits platforms, the hybrid model is the correct starting architecture. Not because automation can't scale, but because edge cases compound over time and manual review capacity needs to be built in from the start.
Frequently Asked Questions
What is an eligibility determination?
An eligibility determination is the formal process of evaluating whether an individual qualifies for a specific benefit or coverage, based on factors like employment status, income, household size, or plan rules. It can be conducted by a caseworker manually or by a software system applying predefined decision logic automatically.
What is AVS for Medicaid?
AVS (Asset Verification System) is an electronic system that state Medicaid agencies use to verify financial assets, such as bank account balances, directly from financial institutions. CMS requires states to implement AVS for certain non-MAGI Medicaid populations, reducing reliance on paper documentation from applicants.
What is the income limit for Medicaid in NC in 2026?
Medicaid income limits vary by eligibility group (adults, children, pregnant individuals, seniors) and are expressed as a percentage of the Federal Poverty Level. For current 2026 thresholds in North Carolina, check the NC DHHS website or benefits.gov directly, as limits are updated annually.
How often does Medicaid check your bank account?
Medicaid agencies use asset verification systems at application and at renewal. Under 42 CFR 435.916, MAGI-based Medicaid eligibility must be renewed once every 12 months and no more frequently, though some states conduct periodic data matching between renewals where permitted.
What is the difference between real-time and batch eligibility determination?
Real-time determination processes each event as it occurs and returns an outcome immediately. Batch processing aggregates records on a set schedule, typically nightly or weekly. For benefits platforms, that lag creates a coverage risk window around hires and terminations that real-time sync removes.
What triggers an automated eligibility re-determination?
Common triggers include a new hire record, a qualifying life event (marriage, birth, divorce, adoption), a change in employment classification or hours, a termination, open enrollment, or a scheduled renewal date. Capturing these events in real time via HRIS or payroll integrations, rather than waiting on a batch export, is what keeps re-determination accurate.


