For benefits administration platforms, HR Tech builders, TPAs, and Insurtech teams, this creates a compounding problem. Manual eligibility processes that work for a handful of employer groups become operationally unsustainable at hundreds. Errors create compliance exposure. Delays erode employee trust.
This guide covers how decision automation for benefits eligibility works end-to-end: the data layer, the rules evaluation pipeline, the determination output, and the factors that separate implementations that hold up from ones that quietly fail.
Key Takeaways
- Decision automation replaces manual HR eligibility review with rules-based logic applied to real-time employment, enrollment, and dependent data.
- The pipeline runs four stages: data ingestion, rules evaluation, determination output, and downstream action triggering.
- Data quality is the primary failure point: stale or incomplete HRIS records produce wrong determinations even with well-written rules.
- Dependent eligibility requires a separate rules layer. Treat it as a distinct data object, not an employee sub-field.
- Regulatory constraints (ACA thresholds, COBRA timelines, ERISA documentation) must be hard-coded into the rules engine and kept current.
What Is Decision Automation for Benefits Eligibility?
Decision automation for benefits eligibility uses predefined rules, conditional logic, and structured data inputs to automatically evaluate whether an individual qualifies for a specific benefit plan. It replaces the manual HR adjudication that would otherwise happen at every trigger point.
The intended output is consistent, auditable eligibility determinations that fire at the right moment: new hire, qualifying life event, open enrollment, or termination. Those determinations then feed directly into enrollment systems or carrier platforms without a human validating the underlying logic each time.
How It Differs from Adjacent Automation
This concept often gets conflated with adjacent automation categories. The distinction matters operationally:
- Benefits enrollment automation covers the employee-facing selection experience: the plan choices an employee sees and interacts with.
- Benefits administration workflow automation handles HR task routing: approvals, reminders, and document collection.
- Eligibility determination automation sits underneath both, evaluating whether someone qualifies before any selection or workflow begins.
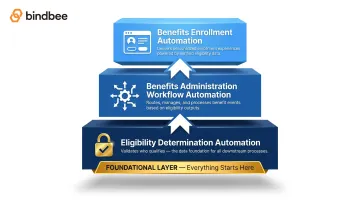
Building enrollment automation on top of a weak eligibility determination layer produces a predictable failure mode: employees who appear eligible but aren't, or vice versa, because the determination logic was never properly isolated and maintained.
Why Manual Benefits Eligibility Processes Break at Scale
Eligibility is not a single rule. It's a compound evaluation across employment status, job classification, hours worked, waiting period end date, dependent relationships, and plan-specific criteria. All of these can change simultaneously, triggered by unrelated events.
The Data Fragmentation Problem
HR teams typically pull eligibility inputs from multiple disconnected systems: HRIS, payroll, time-tracking, and sometimes ATS data for new hires still in onboarding. These systems are rarely synchronized in real time, and the data they hold for the same employee often differs:
- A payroll system may show a status change three days after the HRIS records it
- A time-tracking system may use different classification codes than the HRIS
When eligibility logic runs against fragmented inputs, the determination reflects the data's state, not the employee's actual situation. At scale, across hundreds of employers, that discrepancy compounds.
The Scale Problem for Benefits Platforms
When a platform serves hundreds of employers, each with their own:
- Eligibility rules and waiting period structures
- Benefit plan configurations
- HRIS systems and data models
- Employee classification schemes
...the number of unique eligibility scenarios grows non-linearly. Manual review becomes structurally impossible at scale.
The Compliance Consequence
Incorrect or delayed eligibility determinations carry regulatory weight:
- ACA exposure: Applicable Large Employers that fail to offer minimum essential coverage to at least 95% of full-time employees face 4980H(a) penalties. Offers that are unaffordable or lack minimum value trigger 4980H(b) assessments of $2,000 and $3,000 per affected employee respectively, indexed annually.
- COBRA risk: Employers have 30 days to notify their plan of a qualifying event; plan administrators then have 14 days to issue election notices. Missing these windows creates legal exposure.
- ERISA enforcement: EBSA recovered $1.384 billion in FY 2024 from plans, participants, and beneficiaries. Eligibility documentation and audit trails matter as fiduciary controls.

The Life Event Problem
Marriage, birth, divorce, loss of other coverage, and employment status changes can all trigger eligibility re-evaluation mid-year. Manual processes rarely have real-time triggers to catch these as they occur, creating gaps between when eligibility changes and when the system actually reflects it.
How Decision Automation for Benefits Eligibility Works
The automation pipeline has four core components that must work together for determinations to be accurate and actionable.
Step 1: Data Ingestion and Normalization
Before any rule runs, the system needs clean, normalized inputs for each employee:
- Employment status and job classification
- Hours per week and hire date
- Waiting period end date
- Dependent relationships and qualifying status
- Existing coverage elections
These inputs must come from authoritative sources, and they must be current. If the upstream HRIS record is stale, no rules engine produces a correct determination.
Most implementations break at this step. Benefits platforms connecting to dozens of employer HRIS configurations face a data normalization problem that compounds with scale. Bindbee's unified API connects to 65+ HRIS and payroll systems, including Workday, ADP, BambooHR, Gusto, Rippling, and UKG, and normalizes employment, dependent, and benefits data into a consistent structure regardless of source. The benefits-first data model exposes Employee Benefits, Employer Benefits, and Dependent Benefits as distinct objects, not nested sub-fields.
For legacy systems that only export flat files, an SFTP-to-API bridge processes CSV, XML, and fixed-width formats through the same normalized API endpoints as direct integrations.
Newfront reduced their integration build time from 12 weeks to 48 hours using this infrastructure, with coverage eligibility checks running in real time instead of waiting on spreadsheet exports.
Step 2: Rules Evaluation and Logic Processing
With clean, normalized data flowing in, the rules engine has what it needs to evaluate eligibility. Rules are expressed as conditional logic. A simplified example:
IF employment_status = full-time
AND tenure ≥ 30 days
AND job_classification = eligible
THEN → eligible for medical plan
Real-world rules layer additional complexity:
- ACA measurement periods: The IRS defines full-time as averaging at least 30 hours per week or 130 hours per month, with look-back periods spanning 3–12 months and stability periods of at least 6 months. These thresholds belong in the rules engine as hard-coded logic, not manual calculations.
- Edge-case priority ordering: Employees on leave, variable-hour workers mid-measurement period, and employees changing classification mid-year all require explicit priority ordering within the rule set.
- Event-triggered re-evaluation: Rules run once at hire for static determinations, but must re-run on any data change or life event for ongoing eligibility monitoring.
Step 3: Determination Output and Downstream Action
After a determination runs, three outcomes are possible:
- Eligible: employee queued for enrollment window activation
- Ineligible: record logged with reason codes for auditability
- Exception: incomplete data or rule conflict, routed to human reviewer with context
Each outcome should trigger downstream actions automatically:
- Enrollment window activation
- Carrier file updates (EDI 834 generation or carrier API push)
- Payroll deduction sync
- Employee notification
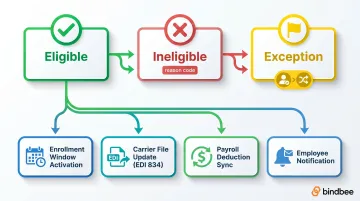
Auditability matters for both compliance and dispute resolution. Every determination should log what data was used, what rule was applied, and what decision was made, with timestamps. When ERISA audits surface, those audit trails are the evidence.
Bindbee's webhook infrastructure supports this downstream orchestration: termination events fire immediately with employment_status=INACTIVE and termination date, enabling COBRA admins and FSA/HSA providers to receive clean data and initiate workflows within the required notice window. ThrivePass used this to cut benefits admin onboarding from 6 weeks to under one week with no manual eligibility checks.
Key Factors That Determine Automation Effectiveness
Data Freshness and Sync Frequency
Eligibility logic is only as accurate as its inputs. An employee whose status changed from part-time to full-time three days ago but whose HRIS record hasn't synced will receive the wrong determination.
BLS JOLTS data shows a 3.4% total separations rate as of March 2026, a baseline indicator of how frequently employment status changes across the labor market. For benefits platforms, this means eligibility re-evaluation isn't a periodic exercise: it's a continuous requirement triggered by individual status changes, not calendar intervals.
That's the operational implication of a 3.4% churn rate at scale: any platform relying on nightly or weekly batch syncs is structurally behind. Bindbee's incremental sync runs automatically after the initial connection, with webhooks firing on employment status changes, hours changes, and dependent enrollment updates, so eligibility re-evaluation triggers as changes occur rather than on a fixed batch schedule.
Dependent Eligibility Complexity
Dependent eligibility adds a second rules layer with its own conditions:
- Age limits (ACA requires plans offering dependent child coverage to extend it until age 26)
- Domestic partner definitions, which vary by plan and state
- Relationship verification for stepchildren, adopted children, and foster children
- Dependent age-out events, which trigger COBRA qualifying event detection
Mercer reports that dependent eligibility audits typically remove 3%–10% of dependents, with average annual incurred medical cost per dependent exceeding $4,570. At scale, ineligible dependents represent direct, avoidable plan overspend.
Dependent data must be treated as a distinct data object, not a sub-field nested under employee records. Bindbee's Dependents model exposes relationship type, date of birth, domestic partner designation, and SSN as normalized fields. These link to a separate Dependent Benefits model that tracks which plans cover each dependent and on what effective dates.
Employer and Plan Configuration Variability
Each employer on a benefits platform may have different:
- Waiting period structures (30-day, 60-day, first-of-month-following)
- Benefit class definitions (e.g., executive class with different offerings)
- Employee classification schemes that don't map consistently across HRIS sources, requiring normalization or lookup tables
The automation layer must support flexible rule configuration per employer: a single logic set applied uniformly will produce systematic errors. Each employer's ruleset needs its own namespace, versioning, and override capability to prevent cross-employer contamination as the platform scales.
Compliance and Regulatory Constraints
Several regulatory requirements impose hard eligibility conditions:
| Regulation | Constraint | Implication for Automation |
|---|---|---|
| ACA 4980H | 30/130 hour thresholds; 3–12 month look-back | Encode thresholds directly; track hours per measurement period |
| COBRA | 30-day employer notice; 14-day admin notice; 60-day election window | Automate qualifying event detection and timeline tracking |
| ERISA | Documentation and audit trail requirements | Log every determination with full data provenance |
| State mandates | State continuation laws, state-specific eligibility rules | Rules engine must support state-level overrides |
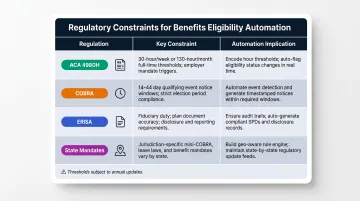
These constraints change. ACA penalty amounts are indexed annually. State mandates evolve. The rules engine must be updatable without requiring a full system rebuild each time thresholds shift.
Common Misconceptions About Benefits Eligibility Automation
A few persistent assumptions lead benefits teams to under-build their automation, and then wonder why determinations drift. These are the ones worth correcting early.
"Eligibility Automation Is a One-Time Setup"
Plan designs update annually. Regulatory thresholds change. Employer configurations evolve as companies reorganize or add benefit classes. Eligibility automation requires ongoing rule maintenance, not just initial configuration. Teams that treat it as a deploy-and-forget system find their rules drifting from reality within months.
"It's a Rules Problem, Not a Data Problem"
Most incorrect eligibility determinations trace back to data issues, not rule logic. Common culprits include:
- Stale records that haven't synced since the last payroll run
- Missing fields required to evaluate waiting periods or benefit class assignment
- Inconsistent classification codes across HRIS sources
A sophisticated rules engine built on unreliable inputs just processes bad data more efficiently. The data infrastructure layer deserves as much engineering investment as the rules logic. Benefits platforms that underinvest in normalized, real-time employment data end up manually reconciling the output of their "automated" system.
"Eligible Means Enrolled"
Determining that someone is eligible and completing their enrollment are two separate operations connected by a downstream trigger. Teams that treat the two as the same thing often discover that eligible employees remain unenrolled because the handoff between determination and enrollment action was never explicitly designed. Without an explicit trigger linking the two pipelines, eligible employees simply sit in limbo, determined but never enrolled.
Frequently Asked Questions
What is automation in insurance?
Insurance automation uses software systems and rules engines to handle processes like eligibility checks, claims routing, policy updates, and enrollment changes that previously required manual staff review. The goal is reduced processing time, fewer errors, and lower administrative cost across high-volume transactional workflows.
What is electronic eligibility?
Electronic eligibility is the digital exchange of eligibility data between systems. For example, an HRIS sending enrollment-qualifying data to a benefits platform or insurance carrier using structured formats like ASC X12 270/271. It enables automated determination and verification without paper-based or phone-based processes.
How does automation benefit employees?
Employees get faster enrollment access (especially during life events), fewer errors in benefit elections, real-time coverage confirmation, and less back-and-forth with HR over eligibility disputes, with enrollment windows opening within hours of a qualifying event rather than days.
What triggers a benefits eligibility redetermination?
The most common triggers are qualifying life events (marriage, birth, adoption, divorce, loss of other coverage), employment status changes (part-time to full-time, leave of absence, termination), annual open enrollment periods, and ACA measurement period outcomes for variable-hour employees.
What data is needed to automate benefits eligibility decisions?
Core inputs include employment status, hire date, job classification, hours worked, waiting period end date, dependent relationships and qualifying status, and existing coverage elections, all sourced from authoritative HRIS and payroll systems in a normalized format, since missing any single field degrades determination accuracy.