

How to Use Ashby API: Complete Guide + Code Examples
Summarise the blog with AI

This guide covers how to integrate with the Ashby API for ATS data access. If you're looking for an easier path, Bindbee connects you to Ashby and 65+ other HRIS, ATS, and payroll systems through one normalized API.
Understanding Ashby API
Ashby is a modern ATS with a REST API that provides access to candidates, jobs, applications, and hiring pipeline data. The API uses API key authentication and supports webhook subscriptions for real-time events.
Key Integration Use Cases
- Candidate status sync: Track candidate progress through the hiring pipeline.
- New hire trigger: Fire onboarding workflows when a candidate is marked as hired.
- Job data: Sync open requisitions and job details into your product.
Integration Methods
Direct API
Ashby's API is developer-friendly with good documentation. Requires API key management per customer, pagination handling, and webhook configuration for event-driven sync.
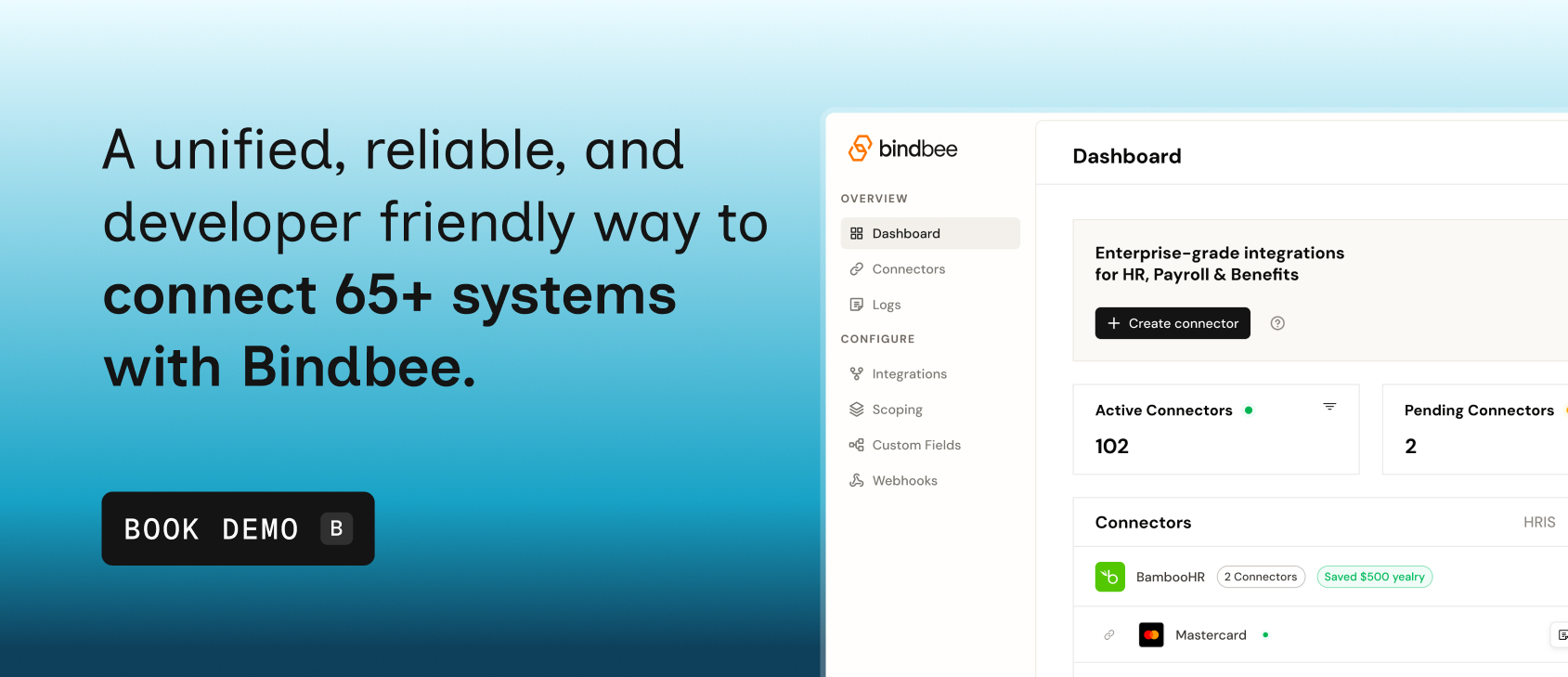
Using Bindbee
Bindbee normalizes Ashby data alongside Greenhouse, Lever, and 65+ other ATS and HRIS systems. One integration covers your entire customer base regardless of which ATS they use.
- Sign up with Bindbee
- Create an ATS connector
- Access normalized candidate and job data immediately
Book a demo to see how Bindbee handles Ashby and 65+ other ATS and HRIS integrations.







